Tracking issues with check-ins
Here's a "best practice" I have come to believe in. Those in the Agile camp might consider it heavy handed and beuracratic. I think it is a heathly compromise that bridges the gap between development groups that "go dark" for extended periods of time, and project management practices that micro manage development's work.
As part of the code line policy (which should state how/when developers check-in their code to a particular branch’s code line), require that developers include the bug/issue identifier as part of their check-in.
I’ve done this in the past with good results. There are a few subtle and positive side effects from this practice (even if entry of the issue number is completely manual):
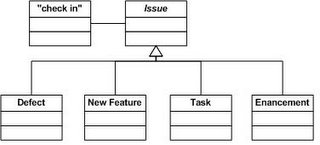
This model allows developers to check in code against a generic “issue” number in the issue tracking system, yet each of these issue types can advance through their own lifecycles and workflows (which they should). Ultimately the configuration of the system is identified as a set of issues and their related change artifacts (the point being, to release the right thing for the right reasons).
This is why a lot of the high-end CM tools provide both a Source Code Control system and a Bug Tracking system. When you buy both from the same vendor, you buy all the hooks required to associate issues with check-ins. Unfortunately, this ties you to a particular issue management, source code management tuple. I would prefer to combine best-of-breed in both.
I have some experience doing this with Atlassian's JIRA and CVS. I think I'll write up the blow-by-blow of that implementation in another blog entry.
As part of the code line policy (which should state how/when developers check-in their code to a particular branch’s code line), require that developers include the bug/issue identifier as part of their check-in.
I’ve done this in the past with good results. There are a few subtle and positive side effects from this practice (even if entry of the issue number is completely manual):
- The combination of an issue tracking system and source code control, in which the check-ins are linked to the issues, is what pushes source code control over the edge into true Configuration Management. The key characteristic being the issue/task management as an abstraction that sweeps up many different change artifacts into a “fix”, “feature” or other discrete package of work. The practice provides the ability to consider groups of check-ins as an atomic unit of work downstream. This is useful in troubleshooting regression, tracking progress, and packaging/release.
- Developers tend to check-in code associated with a specific unit of work (assuming the issues outlined in the issue tracking system are appropriately granular and discrete). The benefit being towards Continuous Integration—in which the code line progresses towards an end state with steady, stable, and identifiable improvements.
- When developers don’t have an issue associated with the work they’re doing, it highlights informality in their work queue management. This path is wrought with landmines, I know, but can be navigated with success. In my experience the delta between a healthy and practical task tracking strategy and fantasy is only dealt with when it affects the developer’s day-to-day activity. The litmus test being how well the issue tracking system reflects the group’s consensus of reality.

This model allows developers to check in code against a generic “issue” number in the issue tracking system, yet each of these issue types can advance through their own lifecycles and workflows (which they should). Ultimately the configuration of the system is identified as a set of issues and their related change artifacts (the point being, to release the right thing for the right reasons).
This is why a lot of the high-end CM tools provide both a Source Code Control system and a Bug Tracking system. When you buy both from the same vendor, you buy all the hooks required to associate issues with check-ins. Unfortunately, this ties you to a particular issue management, source code management tuple. I would prefer to combine best-of-breed in both.
I have some experience doing this with Atlassian's JIRA and CVS. I think I'll write up the blow-by-blow of that implementation in another blog entry.
posted by Steve at 10:40 AM
![]()

0 Comments:
Post a Comment
<< Home